Digging for Gold in Chandra's Archives
October is American Archives Month—a time to celebrate the importance of archives across the country. In honor of Archives Month, we're participating in a pan-Smithsonian blogathon. Throughout October we, and other blogs from across the Smithsonian, will be blogging about Chandra's rich archive of astronomical data, issues, and behind-the-scenes projects.
--------------------------------------------------------------------------------------------------------------------
Summer at the Smithsonian Astrophysical Observatory in Cambridge, MA, is a perfect time for picking up projects that have been sitting on the back burner for a while. As activities slow down a bit, it's great to dig deeper into the Chandra data archive looking for a hidden gem; and when sifting through over 8 terabytes of data comprising more than 10,000 observations from one of NASA's "Great Observatories," you're bound to unearth more than a few.
Chandra has now been in operation for over 12 years, and in that relatively short time has fundamentally changed our understanding of the high-energy universe. From the X-ray signatures of planetary aurorae to the never before seen tell-tale signs of the presence of dark matter in colliding superclusters of galaxies, Chandra's exquisite sensitivity to X-ray light is the key. Nestled deep within the electronics of this space observatory resides a modest 1.8-gigabyte solid state recorder. This is Chandra's hard drive , about the size of a typical USB thumb drive. Data from the telescope's science instruments, as well as telemetry from the spacecraft subsystems, are continually written to this recorder.

Using NASA's Deep Space Network of communications antennae spread around the globe, NASA engineers located at the Chandra Operations Control Center, also in Cambridge, download this data at least twice daily. It is important that these communications passes are consistently maintained. If for some reason the engineers could not download the data, the recorder would eventually fill up and the spacecraft would start overwriting and losing data on the recorder. Once the raw spacecraft data have been downloaded, they are then sent through a processing pipeline to ultimately end up in the Chandra archive. The pipeline categorizes the various data products created by the telescope, and applies standard data reduction algorithms to the observational data to convert it from it's raw unusable state to a finished data product ready for analysis. The data are maintained in the archive typically for a one-year proprietary period, during which only the scientists who requested the data have access to it. At the end of that year, the data become publicly available. After twelve years of science observations for Chandra, there are currently over 10,000 observations in the archive available to the public.
While most of the Chandra public outreach imagery that I work with comes directly from press releases associated with new publications dealing with recent data, there are, scattered throughout the archive, data for which the intended science of the observation never panned out, or a paper was never written. These observations deserve a chance at stardom as well! Of course, mining an archive as large as this is no easy task. Thankfully, the Chandra Source Catalog Project Team has created the definitive catalog of sources observed by Chandra and a number of tools designed for interacting with archive data in novel ways that foster serendipitous discovery. One such tool is the Chandra Source Catalog Google Earth interface, a service that allows you to visualize the entirety of Chandra's source catalog on the sky with Google Earth. With this tool, one simply uses mouse gestures to navigate the sky to discover Chandra observations that are represented by the field of view outline of the Chandra detectors on the sky. The best part is that this is freely available to anyone with the curiosity and desire to explore a much deeper facet of this great observatory.
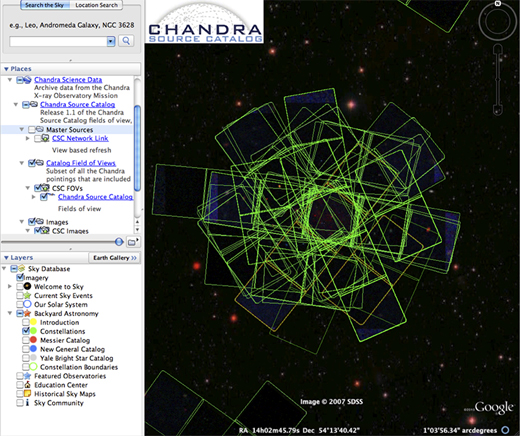
Google Sky Interface
Utilizing this method of data discovery, I have identified a handful of potential Chandra press release images which otherwise would have gone unnoticed. Although this is not a very rigorous approach to scanning the archive for potential images, it is certainly intuitive, and fun! In addition to simply scanning around the sky to see what is there, I've also done targeted searches for objects that could potentially yield interesting images (active galaxies, supernova remnants, etc). Once a potential image is identified, I check that we haven't already done a press release on it, or if we have, that it was an older image with less data that could be updated. The next step is to begin searching the data archives from other telescopes -- sometimes leading to the next "Great Observatories" image combining Hubble optical data with Spitzer infrared and Chandra data . With all of the data collected, the joy of image processing begins with cleaning, combining and coloring the various datasets to create a new multi-wavelength image, but that is the subject of another post.
We truly live in a golden age of astronomy when, for the first time in history, anyone with a little astronomical know-how and motivation can easily access high-level data products from the world's premier observatory archives spanning multiple wavelengths across the electromagnetic spectrum. We all owe an astronomical debt of gratitude to the hard working individuals who've expended an enormous effort designing, building and implementing the infrastructures supporting the archives of the world's observatories as well as the intuitive interfaces needed to access them.
Stay tuned for more posts throughout October on Chandra archival activities, and follow hashtag #archivesmonth on Twitter for other Smithsonian Archives Month posts.
-Joseph DePasquale, Science Imager, Chandra EPO